Amazon ML 解决方案实验室最近与 Kinect Energy 一起合作构建了一个管道服务,用机器学习预测能源未来价格。我们使用 Amazon SageMaker 和 AWS Step Functions创建自动化的数据抽取和数据推理的管道服务,该服务可以自动调度去预测能源价格。
最特别的是这个流程利用了Amazon SageMaker DeepAR 预测算法。 使用全新的深度学习预测模型去替换当前手工流程,我们不仅节约时间,还推动Kinect Energy内部一致使用数据驱动方法论。
下图显示了端到端的解决方案
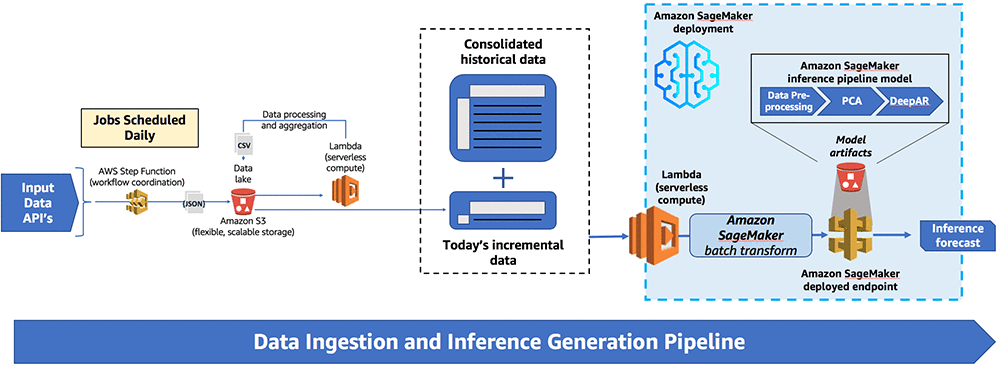
编排一个step function来实现数据抽取流程,即每天加载和处理数据,并将数据存入Amazon S3 数据湖。 之后数据传入Amazon SageMaker,系统通过Batch Transform调用去触发执行推理模型管道服务来生成推理 (Inference).
项目动机
自然能源市场依赖一系列产品来满足市场需求,如风能、水利发电、核能、煤以及石油天然气。真正决定各个能源所占市场比列取决于当天各个能源的市场价格。这个价格取决于那天的电力需求。投资者可以在公开市场竞价交易电力。
Kinect Energy 向客户买卖能源,其商业模式中重要的一部分涉及交易能源价格衍生的金融合同。 这需要对能源价格进行准确的预测。
Kinect Energy 希望通过使用 ML 来改进和自动化预测过程(以前是手动完成的)。现货价格是当前商品价格,而不是未来或远期执行价格, 即商品在将来交割时可以买入或卖出的价格。通过比较预测的现货价格和远期执行价格,Kinect Energy团队有机会根据当下的预测对冲未来价格变动。
数据需求
在此解决方案中我们希望预测以小时为间隔的未来四周的现货价格。项目面临的主要挑战之一是搭建一个系统来自动收集和处理所需的数据。该管道服务需要以下两种数据:
-
历史现货价格
-
能源生产和消费率以及其他影响现货价格的外部因素
(我们将生产和消费率称为外部数据。)
为了构建一个强大的预测模型,我们必须收集足够的历史数据来训练模型,最好是跨越多年的数据。我们还不得不每天在市场产生新信息时更新数据。该模型还需要能够访问放置预测后的结果数据的外部数据源。
供应商每天将每小时现货价格更新到外部数据馈送。多家实体提供生产和消费率的数据, 并且发布数据的时间周期也各有不同。
Kinect Energy 团队的分析师要求在一天中的特定时间预测现货价格,来制定其交易策略。因此, 我们必须构建一个健壮的数据管道, 定期调用多个 API操作。这些操作收集数据,执行所必须的预处理, 然后将数据存储在 Amazon S3 数据湖中, 供预测模型访问这些数据。
数据抽取和生成推理的管道
管道由三个主要步骤组成:数据抽取、数据存储和推理生成。他们都用 AWS Step Function 状态机编排, Amazon CloudWatch 事件会每日调度触发该状态机来准备要消费的数据。
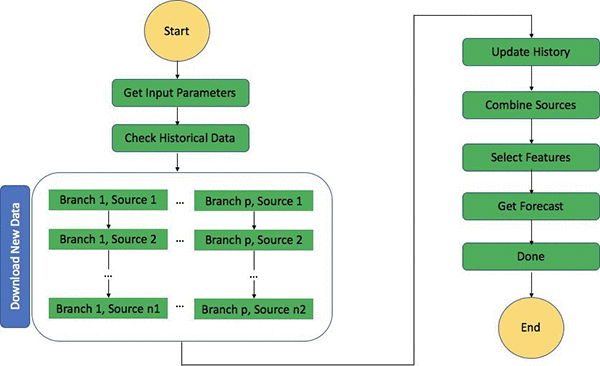
上面的流程图详细介绍了组成整个 Step Function 的各个步骤。Step Function 协调下载新数据、更新历史数据以及生成新的推理, 整个过程可以在单个连续工作流中执行。
尽管我们按照天周期调度构建状态机,但它还是有两种数据获取模式。默认情况下,状态机按天下载数据。但用户也可以手动按需触发下载全量的历史数据,以及进行设置或者恢复流程。该 Step function 调用多个API来收集数据,每种数据都有不同的延迟。数据收集流程并行运行。此步骤还执行所有必需的预处理,并将数据按时间戳作为前缀存储在 S3 中。
下一步是各自追加更新各自的日历史数据。另外还需要处理数据,让数据满足DeepAR所需要的格式,并将处理好的数据发送到另一个指定的文件夹。
之后,模型触发一个 Amazon SageMaker 批量转换任务将数据从那个指定位置拉出,生成预测数据,最终将结果存放在另一个时间戳命名的文件夹中。Amazon QuickSight 报表选取预测结果数据并将其呈现给分析师。
将所需依赖项打包入 AWS Lambda Functions
我们引入 Python pandas和 scikit-learn(sklearn)库来处理大部分数据预处理工作。这些库没默认导入到Lambda Function(Step Function之后要调用)。 所以我们要将 Lambda 函数 Python 脚本及其所需导入的包打包到 .zip 文件中。
cd ../package
pip install requests --target .
pip install pandas --target .
pip install lxml --target .
pip install boto3 --target .
zip -r9 ../lambda_function_codes/lambda_all.zip .
cd -
zip -g lambda_all.zip util.py lambda_data_ingestion.py
下面代码是把 .zip 文件上传到指定 Lambda Function
aws lambda update-function-code
--function-name update_history
--zip-file fileb://lambda_all.zip
异常处理
编写健壮的生产代码的一个常见挑战是预测可能的故障机制并消除它们。如果没有处理异常事件的指示,管道可能会崩溃。
我们的管道存在两大故障隐患。首先,我们的数据抽取依赖于外部 API 数据馈送, 这些馈送可能会宕机,从而导致查询失败。在这种情况下我们会尝试重连,在尝试一个给定的固定次数后,数据抽取流程标记数据馈送暂时不可用。其次, 数据馈送可能无法提供新数据,而是返回旧信息。在这种情况下, API不会返回错误,但我们的流程需要有自行判断信息是否为新信息的能力。
Step Functions 提供重试选项来自动化重试流程。根据异常的性质,我们可以设置两次连续尝试的间隔(IntervalSeconds)和尝试操作的最大次数(MaxAttempts)。参数 BackoffRate=1 代表按定长间隔尝试,而 BackoffRate=2 表示每个当前间隔是前一个间隔的两倍。
"Retry":[
{
"ErrorEquals":[
"DataNotAvailableException"
],
"IntervalSeconds":3600,
"BackoffRate":1.0,
"MaxAttempts":8
},
{
"ErrorEquals":[
"WebsiteDownException"
],
"IntervalSeconds":3600,
"BackoffRate":2.0,
"MaxAttempts":5
}
]
数据获取模式的灵活性
我们构建了的 Step Function状态机可以提供两种不同数据获取模式。
-
从整个现有历史记录里抽取历史数据
-
从每日增量数据中抽取新数据
Step Function 通常只需在开始时提取一次历史数据并将其存储在 S3 数据湖中。随着状态机追加最新的天数据,存储的数据会增长。 CheckHistoricalData 这一步会调用的 Lambda Function 里有个参数叫做 full_history_download。 将它设置为 True 就会刷新整个数据集。
import json
from datetime import datetime
import boto3
import os
def lambda_handler(payload, context):
if os.environ['full_history_download'] == 'True':
print("manual historical data download required")
return { 'startdate': payload['firstday'], 'pull_type': 'historical' }
s3_bucket_name = payload['s3_bucket_name']
historical_data_path = payload['historical_data_path']
s3 = boto3.resource('s3')
bucket = s3.Bucket(s3_bucket_name)
objs = list(bucket.objects.filter(Prefix=historical_data_path))
print(objs)
if (len(objs) > 0) and (objs[0].key == historical_data_path):
print("historical data exists")
return { 'startdate': payload['today'], 'pull_type': 'daily' }
else:
print("historical data does not exist")
return { 'startdate': payload['firstday'], 'pull_type': 'historical' }
构建预测模型
我们用 Amazon SageMaker 构建了ML模型。当收集完历史数据集合进入S3后,我们使用 Python库(如 pandas 和 sklearn)来清理和准备这些数据。
我们用 Amazon SageMaker ML 算法里一个独特的算法,主成分分析 (PCA) 算法来做特征工程。我们在训练预测模型之前对数据集做主成分分析 (PCA) 是为了降低特征空间并保留有用信息和创建新的所需特征。
我们用 Amazon SageMaker ML 算法里一个独特的算法,叫做 DeepAR 来做预测模型。DeepAR 是一个自定义预测算法,专门处理时间序列数据。Amazon 最初使用该算法进行产品需求预测。它能够基于时序数据和不同外部因素预测客户需求,所以选该算法来预测能源价格波动也是可行的。
下图显示了一部分建模结果。用历史数据训练模型后,我们把模型放在可用的 2018 数据上测试。使用 DeepAR 模型的一个好处是,它返回一个 0.1-0.9 的置信度得分,提供预测的可信度。放大观察预测的不同时间段数据,我们可以看到与实际价格记录相比,DeepAR 确实擅长重现过去的周期时序模式。
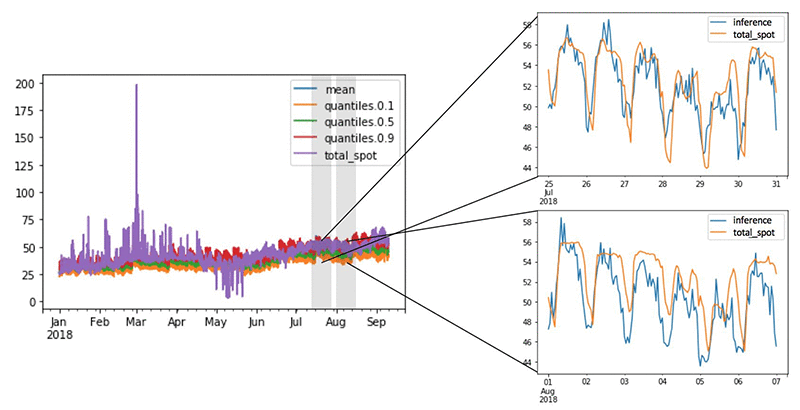
上图显示了 DeepAR 模型预测的值与测试集2018年1月至9月的实际值之间的比较。
Amazon SageMaker 还提供了一种执行超参数优化 (HPO) 的简单方法。模型训练后,我们可以调优模型的超参数来获得更佳的模型性能。Amazon SageMaker HPO 利用贝叶斯优化搜索超参数空间,并搜索出不同模型的理想参数。
Amazon SageMaker HPO API 简化资源约束流程(如分配给流程的训练作业数和计算能力)。我们选择对 DeepAR 内部重要的常见参数做测试,例如 dropout rate、embedding维度和神经网络中的层数。
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
objective_metric_name = 'test:RMSE'
hyperparameter_ranges = {'num_layers': IntegerParameter(1, 4),
'dropout_rate': ContinuousParameter(0.05, 0.2),
'embedding_dimension': IntegerParameter(5, 50)}
tuner = HyperparameterTuner(estimator_DeepAR,
objective_metric_name,
hyperparameter_ranges,
objective_type = "Minimize",
max_jobs=30,
max_parallel_jobs=2)
data_channels = {"train": "{}{}/train/".format(s3_data_path, model_name),
"test": "{}{}/test/".format(s3_data_path, model_name)}
tuner.fit(inputs=data_channels, wait=False)
用Amazon SageMaker 管道模型和 sklearn容器打包模型
为有效实现和部署ML模型,我们必须确保输入数据格式和推理处理的数据格式以及和训练模型时处理的数据格式都匹配。
在用DeepAR训练模型之前,模型管道使用 sklearn 函数进行数据处理,转换以及特征工程PCA。为了在自动化管道中保存上述流程,我们使用预安装 sklearn 容器的 Amazon SageMaker 和 Amazon SageMaker 推理管道模型。
在 Amazon SageMaker SDK 中,有一堆 sklearn classes 可以处理端到端的训练和部署自定义sklearn代码。例如,以下代码显示在托管环境中执行一个sklearn Estimator的sklearn脚本。托管的 sklearn 环境是一个 Amazon Docker 容器,用于执行在entry_point Python 脚本定义的函数。同时我们提供 .py 后缀名的预处理脚本文件。 Amazon SageMaker sklearn模型在训练数据上收敛后,我们就可以让收敛的模型处理推理时间点的数据啦。
from sagemaker.sklearn.estimator import SKLearn
script_path = 'sklearn_preprocessing.py'
sklearn_preprocessing = SKLearn(
entry_point=script_path,
train_instance_type="ml.c4.xlarge",
role=Sagemaker_role,
sagemaker_session=sagemaker_session)
sklearn_preprocessing.fit({'train': train_input})
之后,我们用 Amazon SageMaker 推理管道按照模型执行顺序连一起。 Amazon SageMaker SDK里的 PipelineModel 类可以线性连接2到5个处理数据推理请求的容器。通过该方法,就可以定义任意组合的Amazon SageMaker算法或自定义算法,打包部署在Docker容器里。
与其他 Amazon SageMaker 模型端点一样,该过程将管道模型调用作为一连串的HTTP请求。管道中的第一个容器处理初始请求,然后第二个容器处理中间响应,等等。管道中的最后一个容器最终将结果返回给客户端。
在构造PipelineModel时,一个关键的考虑因素是注意每个容器数据输入和输出的数据格式。例如DeepAR 模型训练时候需要特殊的数据格式作为输入,推理的时候需要一行JSON格式数据。这种情况和监督类ML模型不一样是因为预测模型往往需要额外的元数据,如时间序列数据的开始日期和时间间隔。
from sagemaker.model import Model
from sagemaker.pipeline import PipelineModel
sklearn_inference_model = sklearn_preprocessing.create_model()
PCA_model_loc="s3://..."
PCA_inference_model = Model(model_data=PCA_model_loc,
image=PCA_training_image,
name="PCA-inference-model",
sagemaker_session=sagemaker_session)
DeepAR_model_loc="s3://..."
DeepAR_inference_model = Model(model_data=DeepAR_model_loc,
image=deepAR_training_image,
name="DeepAR-inference-model",
sagemaker_session=sagemaker_session)
DeepAR_pipeline_model_name = "Deep_AR_pipeline_inference_model"
DeepAR_pipeline_model = PipelineModel(
name=DeepAR_pipeline_model_name, role=Sagemaker_role,
models=[sklearn_inference_model, PCA_inference_model, DeepAR_inference_model])
搭建完成后,会发现使用一个模型管道的好处是单端点就能处理生成推理。除了确保对训练数据的预处理与推理时间点匹配上,部署单端点可以让从数据输入到生成推理在一个流程里完成。
## 使用批量转换进行模型部署
我们使用 Amazon SageMaker 批量转换来处理生成推理。我们可以通过两种方式中的其中一种在 Amazon SageMaker 中部署模型:
- 建一个持久 HTTPS 端点,其中模型提供实时推理。
- 运行 Amazon SageMaker 批量转换作业,该作业启动端点,基于存储的数据集生成推理,输出基于推理的预测数据,然后关闭端点。
由于这个能源预测项目的实现要求,用批量转换实现是更好的选择。Kinect Energy 希望定时每日收集数据和预测价格,然后用于交易分析,而不是实时预测。这个解决方案里面,Amazon SageMaker 负责启动、管理和关闭所需的资源。
DeepAR 最佳实践建议, 训练和推理的阶段都应该向模型提供完整的历史时序数据,数据要包含目标和动态特征。这是因为模型使用更靠前的数据点来生成滞后要素,所以输入数据集可能会变得非常大。
为了避免通常的 5-MB 请求消息体限制,我们使用推理管道模型创建了批处理转换,并使用 max_payload 参数设置了输入数据大小的限制。然后,我们使用在训练数据上使用的相同函数生成输入数据,并将其添加到 S3 文件夹中。然后我们可以将批量转换作业指向此位置,并生成基于该输入数据的推理。
input_location = "s3://...input"
output_location = "s3://...output"
DeepAR_pipelinetransformer=sagemaker.transformer.Transformer(
base_transform_job_name='Batch-Transform',
model_name=DeepAR_pipeline_model_name,
instance_count=1,
instance_type='ml.c4.xlarge',
output_path=output_location,
max_payload=100)
DeepAR_pipelinetransformer.transform(input_location, content_type="text/csv")
自动推理生成
最后,我们创建了一个 Lambda 函数来生成每日预测。为了让 Lambda可以调用,我们将代码转换为 Boto3 API。
Amazon SageMaker SDK 库允许我们访问和调用经过训练的 ML 模型,但是模型远远大于Lambda 函数中限制50 MB。所以我们使用原生的 Boto3 库。
# Create the json request body
batch_params = {
"MaxConcurrentTransforms": 1,
"MaxPayloadInMB": 100,
"ModelName": model_name,
"TransformInput": {
"ContentType": "text/csv",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": input_data_path
}
},
},
"TransformJobName": job_name,
"TransformOutput": {
"S3OutputPath": output_data_path
},
"TransformResources": {
"InstanceCount": 1,
"InstanceType": 'ml.c4.xlarge'
}
}
# Create the SageMaker Boto3 client and send the payload
sagemaker = boto3.client('sagemaker')
ret = sagemaker.create_transform_job(**batch_params)
结论
与 Kinect Energy 团队一起,我们最终完成了创建自动数据抽取和推理生成管道。我们使用 AWS Lambda 和 AWS Step Function来自动执行和调度整个流程。
我们在 Amazon SageMaker 平台中构建、训练和测试了 DeepAR 预测模型来预测电力现货价格。 Amazon SageMaker 推理管道整合了预处理、特征工程和模型输出步骤。单个 Amazon SageMaker 批量转换作业就可以将模型投入生产并生成推理。这些推理现在帮助 Kinect Energy 公司对现货价格做出更准确的预测,并提高其电价交易能力。
Amazon ML 解决方案实验室提供的模型开箱即用。同时我们也有机会在数据科学实践方面培训 Kinect Energy 团队,方便他们能够维护、迭代和改进在机器学习方面的 工作。他们可以利用目前资源扩展到未来其他的用例。
本文为翻译,原文章地址按这里